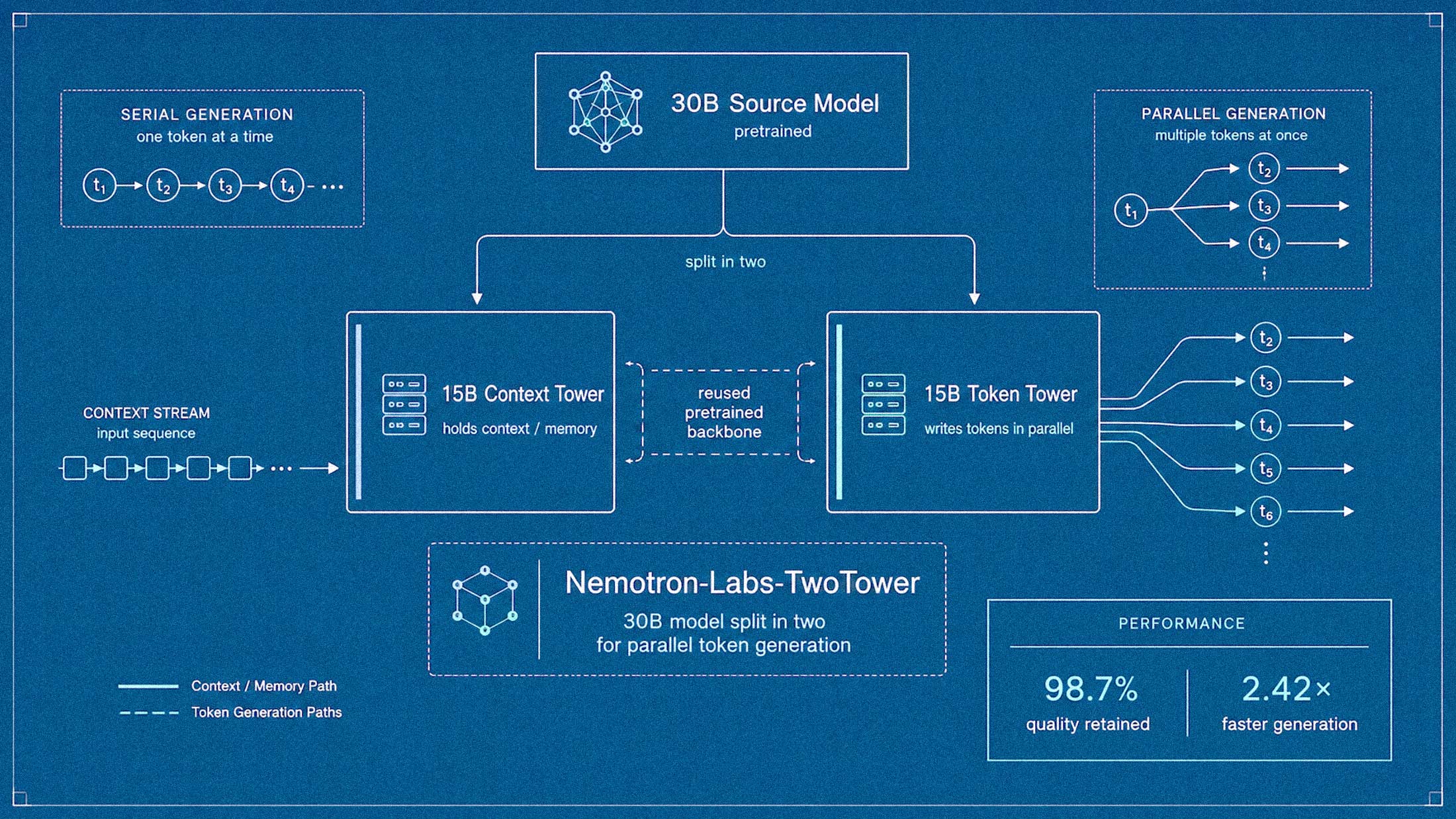
Language models write one word at a time. That sequential bottleneck has defined the entire inference stack since GPT-2. NVIDIA Research has released Nemotron-Labs-TwoTower, an open-weight model that tries something different: split the 30-billion-parameter Nemotron-3-Nano into two copies, assign each a specialized role, and generate tokens in parallel.
The approach yields 2.42 times the wall-clock throughput of the autoregressive baseline while retaining 98.7 percent of its quality on aggregate benchmarks. The model ships under NVIDIA's permissive open license, ready for commercial use.
How It Works
Traditional autoregressive models decode tokens sequentially. Each forward pass produces one token, and the next pass depends on that output. Diffusion language models take a different path, generating multiple tokens simultaneously and refining them iteratively. But most diffusion models force a single network to do two jobs: represent the clean context and denoise corrupted tokens at every step.
TwoTower separates these responsibilities. One network, the context tower, processes the prompt and all previously committed tokens in standard autoregressive fashion. It produces key-value caches and recurrent states. The second network, the denoiser tower, takes noisy token blocks and refines them through a mask-diffusion process, attending bidirectionally within each block and causally to the context tower's outputs.
Both towers start as copies of the same Nemotron-3-Nano-30B-A3B checkpoint. The context tower stays frozen. Only the denoiser is trained, using roughly 2.1 trillion tokens. That's a fraction of the 25-trillion-token pretraining corpus the original backbone consumed.
We took a 30B model and split it in two to write tokens in parallel instead of one at a time.
— NVIDIA AI (@NVIDIAAI) July 1, 2026
Introducing Nemotron-Labs-TwoTower: a diffusion language model from NVIDIA Research adapted from Nemotron-3-Nano-30B-A3B. Here’s how it works: one half holds the context, the other… pic.twitter.com/Uza5QAO7N9
Architecture Details
The underlying backbone is a hybrid design that interleaves Mamba-2 state-space layers, self-attention, and mixture-of-experts blocks. Each tower contains 52 layers: 23 Mamba-2, 6 self-attention, and 23 MoE. The MoE layers use 128 routable experts with 6 active per token, plus 2 shared experts. Total parameters across both towers reach approximately 60 billion, though active parameters per token remain around 3 billion per tower.
The denoiser introduces a few modifications. Attention within noisy blocks operates bidirectionally rather than causally. Layer-aligned cross-attention connects each denoiser layer to the corresponding context tower layer. And a timestep conditioning mechanism modulates every layer based on where the diffusion process currently sits.
Benchmark Results
General knowledge tasks remain within about one point of the autoregressive baseline. Commonsense and multilingual performance hold or slightly improve. Code and math show modest degradation. HumanEval drops from 79.27 to 75.58, a roughly four-point decline. NVIDIA notes that pushing throughput past 3x comes with larger quality losses, suggesting a fundamental tradeoff curve that practitioners will need to navigate.
The released checkpoint is a base model, not instruction-tuned or aligned. Running full two-tower diffusion requires two GPUs at about 59 gigabytes each in BF16 precision. A single 80-gigabyte GPU can run the autoregressive-only mode if the diffusion capability isn't needed.
Why This Matters
Inference cost dominates the economics of large-scale language model deployment. Any technique that delivers more tokens per second at acceptable quality has immediate commercial relevance. TwoTower's approach of adapting an existing pretrained backbone rather than training a new model from scratch also matters for teams that want diffusion capabilities without the compute bill of a full pretraining run.
The single-checkpoint flexibility is worth noting. Teams can switch between diffusion mode, mock-AR mode, and standard autoregressive decoding depending on deployment constraints. The context tower retains its LM head for speculative decoding or likelihood evaluation when needed.
NVIDIA has been building toward this moment. The company released Nemotron 3 Ultra for complex agentic workloads and published Nemotron-Labs-Diffusion earlier this year, a tri-mode model that unifies autoregressive, diffusion, and self-speculation decoding. TwoTower adds another option to the toolkit, specifically optimized for throughput-sensitive inference.
The research paper lists Fitsum Reda, John Kamalu, Roger Waleffe, Mostofa Patwary, Mohammad Shoeybi, and Bryan Catanzaro as authors. The paper and weights are available now on arXiv and Hugging Face.