
Anthropic released Claude Opus 4.7 today, positioning it as the company's most capable model for extended, complex tasks that require minimal human oversight. The update focuses heavily on what the company calls "agentic" performance: the ability to execute multi-step workflows reliably without constant supervision.
The Core Problem Opus 4.7 Addresses
Large language models have grown increasingly capable at individual tasks, but deploying them on longer workflows remains frustrating. Models drift from instructions, produce outputs that need constant verification, and require human intervention at nearly every step. Anthropic built Opus 4.7 specifically to address these failure modes.
The company claims three primary improvements: stricter instruction following, built-in self-verification of outputs, and reduced supervision requirements. In practice, this means the model should stay on task during extended coding sessions, document generation, or research workflows without wandering off or producing work that needs to be redone.
For organizations running AI on production systems, the reliability improvements matter more than raw capability gains. A model that completes 95% of tasks correctly but requires human review on every output isn't meaningfully autonomous. Opus 4.7 aims to push that number high enough that human oversight becomes exception-handling rather than quality control.
Vision Gets a Substantial Upgrade
The update delivers what Anthropic describes as over 3x resolution improvement for image analysis. This isn't incremental. Previous vision capabilities struggled with detailed technical documents, dense interfaces, and professional materials like presentation slides or architectural drawings.
The enhanced vision targets specific professional use cases: analyzing UI mockups, reading complex charts, processing multi-page documents with mixed text and graphics. For teams using AI to generate or review interface designs, the improvement should reduce the back-and-forth cycle of corrections.
This positions Opus 4.7 against competitors like OpenAI's GPT-4o and Google's Gemini, both of which have pushed multimodal capabilities as key differentiators. The resolution jump suggests Anthropic is taking the vision competition seriously rather than treating it as a secondary feature.
New API Controls for Cost and Priority
Two API additions accompany the release. The first is an "xhigh" effort level that allows developers to explicitly request more computational resources for demanding tasks. The second introduces task budgets that let organizations set cost and priority parameters for different workflows.
These controls reflect the reality that not every query deserves the same resources. A quick question shouldn't consume the same budget as a complex coding task. The budget system lets organizations differentiate between routine operations and high-value workflows that justify additional compute.
For enterprises managing AI costs across multiple teams and applications, this granularity matters. Without it, organizations either overspend on simple tasks or underprovision complex ones. The competition from open-source models has made cost efficiency a genuine concern, even for organizations committed to commercial APIs.
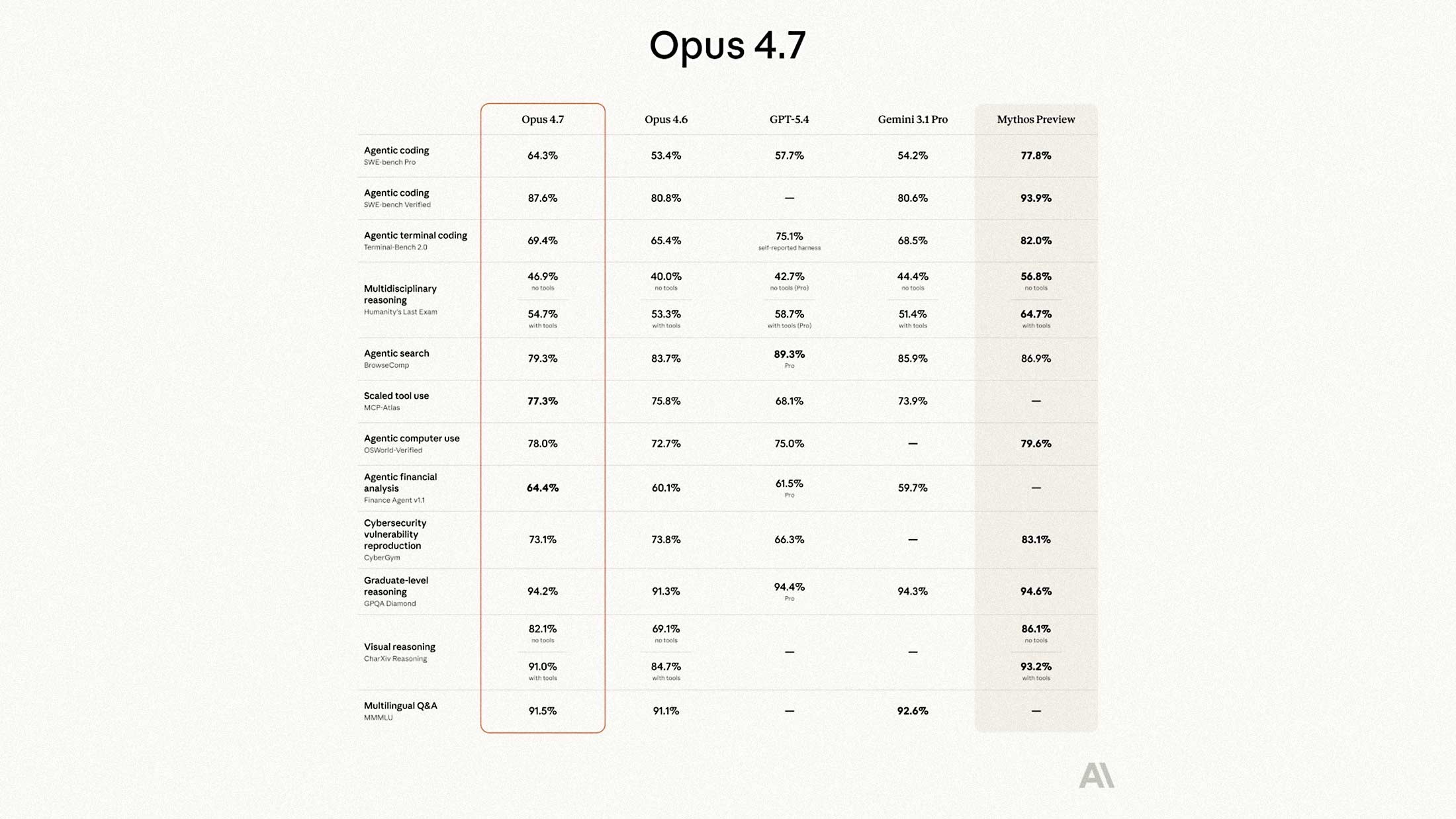
Benchmark Performance
Anthropic's internal benchmarks show Opus 4.7 outperforming both the previous Opus 4.6 and competing models on agentic coding and reasoning tasks. The specific gains vary by task type, with the largest improvements appearing in extended coding sessions and multi-step research workflows.
Independent verification will take time, but early access users have reported noticeable improvements in instruction adherence. The company's previous work on code analysis suggests the engineering team has genuine depth in this area.
Opus 4.7 is available immediately on claude.ai and through major cloud platforms including Amazon Bedrock and Google Cloud's Vertex AI. Pricing remains unchanged from Opus 4.6, which positions the release as a capability upgrade rather than a premium tier.


