The race to build foundation models for 3D reconstruction has produced some impressive entries over the past year. Models like DA3 and VGGT demonstrated that transformers could generalize across scenes and geometries in ways that traditional structure-from-motion pipelines never could. But they shared a fundamental limitation: they processed frames in batches, not streams. For real-time applications like robotics, AR, and autonomous navigation, that distinction matters enormously.
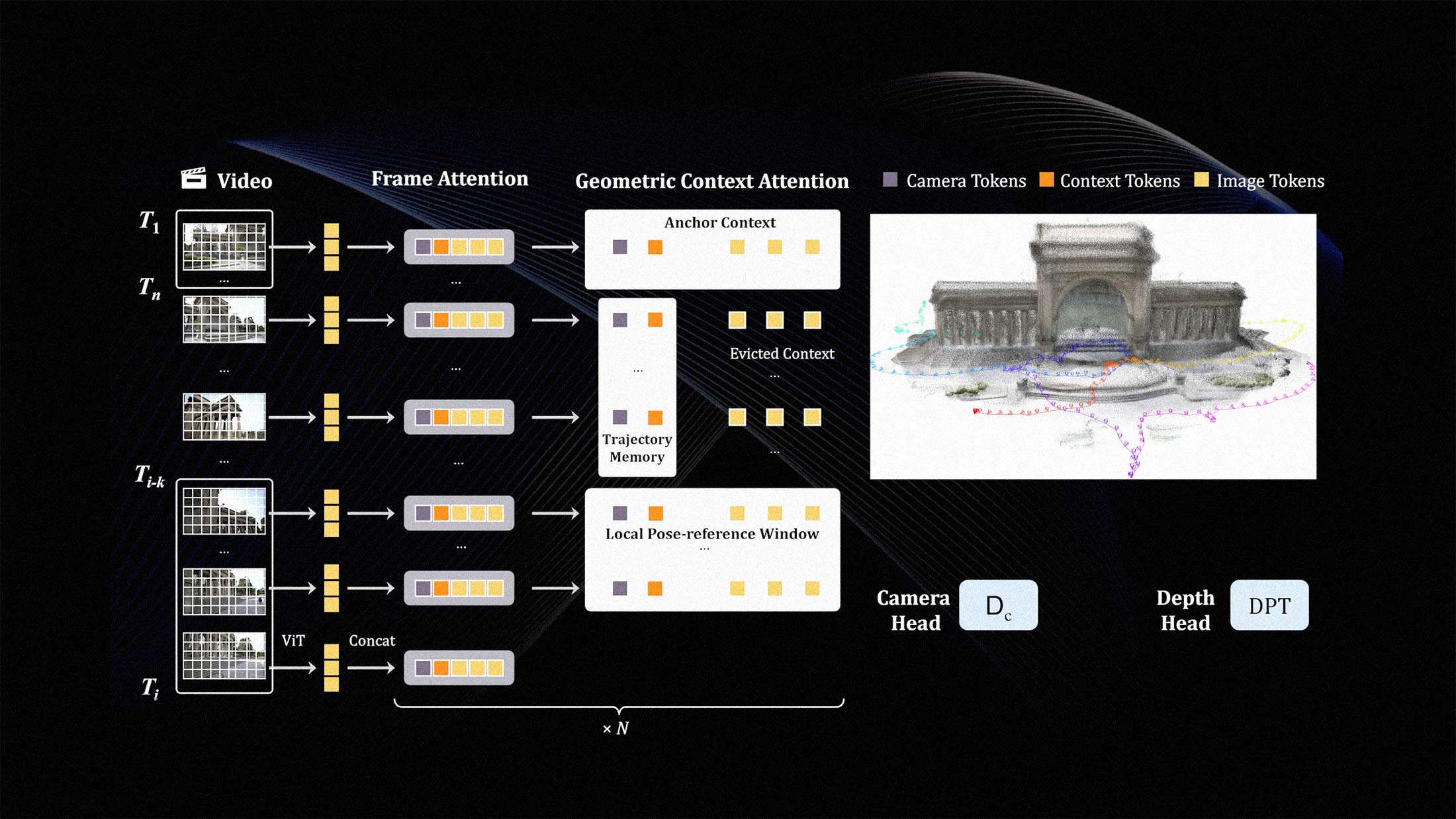
LingBot-Map, a new 3D foundation model released this week, takes a different architectural bet. It's purely autoregressive, meaning it processes video frames sequentially and maintains a persistent spatial representation that updates with each new observation. The model reports achieving roughly 20 frames per second at 518×378 resolution over sequences exceeding 10,000 frames. Those numbers suggest something that previous approaches couldn't deliver: continuous 3D mapping without the computational cliff that comes from holding entire sequences in memory.
Why Autoregressive Matters Here
Most existing 3D foundation models treat reconstruction as a set-to-set problem. You feed in a collection of images, the model reasons about correspondences and geometry, and you get a point cloud or depth map out the other end. This works well for offline applications where you have all your data upfront. It falls apart when you need to reconstruct the world as you move through it.
The autoregressive approach inverts this. Instead of accumulating frames and processing them together, LingBot-Map maintains an internal state that represents its current understanding of the scene. Each new frame refines that state rather than requiring a complete recomputation. The technical paper describes this as a form of learned spatial memory, similar in spirit to how SLAM systems maintain maps, but with the generalization capabilities of large-scale pretraining.
The 10,000-frame benchmark is particularly notable. Previous models degraded significantly over long sequences as memory requirements grew quadratically with frame count. LingBot-Map's linear scaling means it can handle the kind of extended exploration that real-world robots and AR devices actually need to perform.
Performance in Context
Twenty frames per second at 518×378 resolution isn't going to compete with dedicated SLAM systems running on optimized hardware. Traditional visual odometry pipelines can hit hundreds of FPS on commodity GPUs. But those systems can't generalize. They require careful tuning for specific camera configurations, fail on novel environments, and produce sparse reconstructions that need separate densification steps.
LingBot-Map sits in a different category. It's a foundation model designed to work out of the box across diverse scenes and sensor configurations. The 20 FPS figure represents a floor for real-time viability rather than a ceiling for speed. And the dense reconstructions it produces include semantic information that pure geometric approaches miss entirely.
The resolution constraint is worth watching. At 518×378, you're working with roughly a quarter of standard 1080p video. That's sufficient for navigation and basic scene understanding but may limit applications requiring fine detail. The paper suggests that resolution scaling remains an active area of development.
The Robotics Connection
The model's name hints at its intended application space. Robotics has been waiting for 3D perception systems that combine the generalization of modern AI with the real-time performance of classical approaches. LingBot-Map represents one possible answer to that challenge.
For mobile robots exploring unfamiliar environments, the ability to maintain a coherent 3D map over thousands of observations without performance degradation is fundamental. Current systems often segment exploration into discrete mapping sessions precisely because their reconstruction pipelines can't handle unbounded sequences. A streaming foundation model changes that calculus.
Spatial AI has become a crowded field over the past year, with multiple companies and research labs racing to build the perception backbone for embodied agents. LingBot-Map's autoregressive architecture represents a meaningful departure from the dominant batch-processing paradigm. Whether that architectural choice proves superior in practice will depend on benchmarks that don't exist yet. The standard 3D reconstruction datasets weren't designed for streaming evaluation.
What's clear is that the engineering constraints are shifting. Foundation models for 3D perception are moving from proof-of-concept to deployment-ready, and the specific tradeoffs they make are starting to matter.


